So you found a bug in one of Microsoft’s great works of software art. What do you do now? I realized that there isn’t a nice step-by-step guide online, so I will give you the low-down on how this process works. It’s not straightforward — Microsoft is a large company, and has probably thousands of calls or reports each day from people who don’t know how to open the File menu. Unfortunately, for those of us in the software development industry, there isn’t a quick or easy way to report actual bugs.
The Bug
My bug that I found has to do with Excel 2016. At my company, we have many spreadsheets that use a feature in Excel called “Web Queries“. These allow one to download a web page, or a table that is on the web page, into cells in your excel document.
In my particular case, I am using this feature to connect our internal job tracking system that I developed to spreadsheets that are used for calculating pricing and energy savings (our company makes energy savings updates to refrigeration systems), and upload that result back to the tracking system.
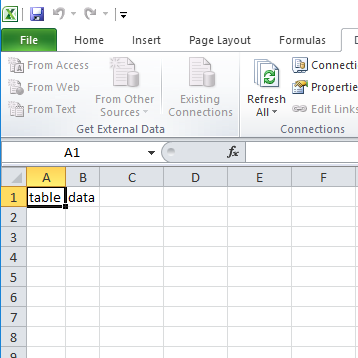
In Excel 2010, and Excel 2013, this works well. However, I have discovered recently that in Excel 2016 (at least for Office 365 version 16.0.8067.2115) the web query downloads the entire web page and not the selected table. This means lots of extra data is coming into the spreadsheet that is not expected, overwriting other cells in the sheet, and causing many things not to work.
Step 1: Search for Existing Reports, Reduce Use Case
The Internet is great for sharing misery of issues with applications that have known limitations. Look for any help on Excel, there’s usually a boatload of hits on google. However, in this case, I found surprisingly little online, maybe a few that could be related, but people have worked around it with VBA macros, and other things. I don’t have that luxury, since the sheer number of files I would have to update makes this very time consuming.
Any good software engineer knows, before reporting a bug to the organization that owns the software, the most helpful thing you can do is reduce it to the minimal case. In my case it is easy. I created an html page that had one table on it:
Using excel, I created a new document in 2016, and added the web query. The way this is done is to select the “From Web” button on the Data ribbon:
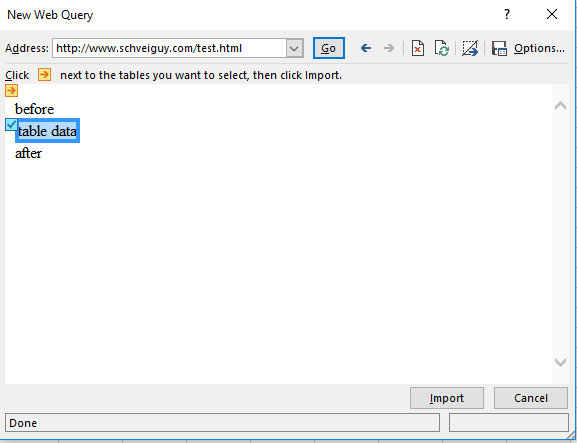
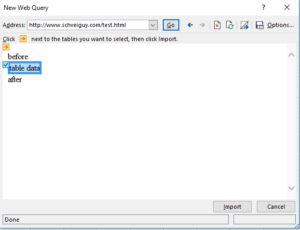
This will bring up a web browser (it’s actually Internet Explorer), allowing you to select both the page, and any sub-table you wish. Here I’ve pointed at the aforementioned web page, and selected the single table for import:
Finally, click the Import button at the bottom, and you get the error I was talking about:
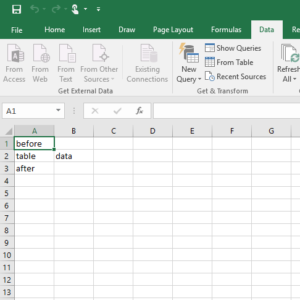
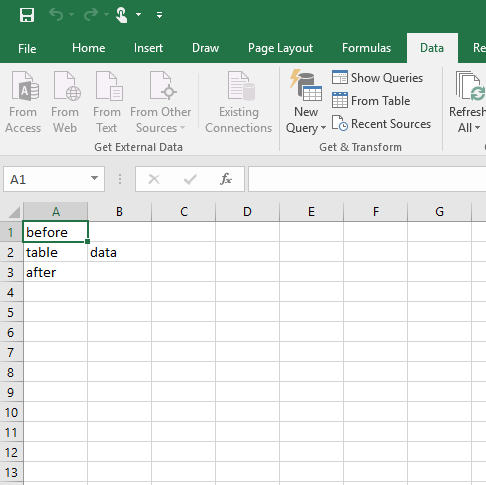
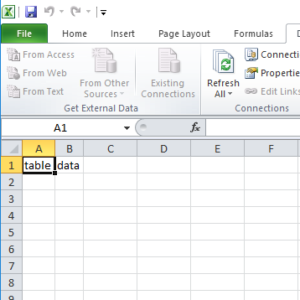
The correct result should be to import only the table data, and not the “before” or “after” text. Here is how it looks on Office 2010:
Now that we have a very reduced, and obvious bug, we can proceed to the next level, which is contacting Microsoft directly.
Level 1: Microsoft Chatbot
Microsoft has a chat bot that will try to help you with answers to questions using some advanced AI. It doesn’t take long to defeat this foe, as this is your standard search of the knowledge base, and you can simply say “No, this doesn’t answer my question”. Eventually, it will attach you to a live agent in the chat window.
Note to Reader: I did not capture any of these sessions as screenshots or logs, unfortunately, so I will describe as best I can the interactions between me and the support staff.
Level 2: Installation Support
Regardless of what you have told the chatbot, or how technical you sound, the first level of Live human support is an installation technician. These are the people who can service the “I can’t find the File menu” support requests. Understandably, these people have much automation at their disposal, and training in how to deal with these kinds of issues. You will get responses to your questions such as “I understand that you are having problems with your web queries in Excel. I’m so sorry for your experience, I’ll be asking you a series of questions to assist you in fixing this issue” and “I understand that you think this is a bug in Excel. I’m so sorry you feel that way, I’ll ask you a few more questions to assist you in fixing this issue.”
The chinks in the armor of these combatants are plain to see — they have buttons to click that repeat what you say, and eventually show the nature of their game. After a few button clicks and repetition, you get something along the lines of “Your problem needs to be handled by the next level of support. Unfortunately, this cannot be done over a chat session. The best option is to call …” and so on. Congratulations, you have graduated to the next world of the Microsoft Support Infrastructure! Here is where you now need to come out of that computer and into the real world with real people.
Level 3: Office 365 Installation Technician
After being on hold for about 5 minutes, you finally get to show them that you actually have technical experience, and explain the real issue to a living breathing person, not augmented with automated responses. The technician in this case is not trained really on the underlying technology of Excel or any other Microsoft products. Finding the File menu is just about all they know. It doesn’t take long to KO this Glass Joe, and move on to the next level. What you are looking for here is “I’m not trained in this area, so I’m going to escalate you to Level 2 technical support.” Note that at Microsoft, even though we are on Level 3, the technicians are trained to attempt deception at every turn. Saying you were really only on Level 1 is a clever use of psychology to try and dampen your spirits. But cheer up, we will prevail!
Level 4: “Level 2” Technician
At this point, you are on hold, and your phone call is stretching past 30 minutes. This is another technique employed by the technicians. Usually you will hear some great news about Windows 10 on the hold line, “now that it is released”, and some of the amazing things you can accomplish. The message here is clear “Microsoft is huge, and you are just one lowly Office 365 licensee. You really should hang up if you know what’s good for you.” I know you have things to do, and it is tempting to give up, but patience is a virtue, and Windows 10 is pretty amazing ((When compared to Windows Vista or Windows 8)), so don’t give up yet!
Finally when you achieve a connection to the L2T, you will finally have the ear of a technical person. “Finally,” you think, “someone who will understand this issue.” This person will use a web applet to actually take over your Windows computer and allow you to show him exactly the issue. You use your minimal test case to prove beyond a doubt that the issue is definitely caused by Office 2016.
The truth is, this person does understand your issue, but his job is not to help you report it. His job is to find loopholes — Loopholes that allow Microsoft to defeat you and send you back to the File menu-finding engineers.
L2T: Can I have your microsoft id?
Me: Yes, it’s redacted@redacted.com
L2T: Let me look up your information. It shows here you have Office 365 Home. We are actually a support office for Commercial users of our product. We have a special division of support that can help you with your Office 365 issues. Let me connect you.
Level 5: The Deflection Specialist
At this point, you have been on the phone for about 45 minutes, and the impatience is growing inside you. You have suffered your first “defeat”, but really it was a victory. Again remember, Microsoft’s deception training is very prevalent in all their support staff. Even though it seems you have been shoved back to the File-menu engineers, you have actually been passed to a special department of Office 365 support called the “Deflection Department”. This department’s job is basically to lie. They make up any excuse or technical jargon to try and get you off the phone.
After you explain your bug ((Note: this isn’t verbatim, but I kid you not, this was the gist of our conversation)):
Deflection Specialist: OK, so you have a file that works with 2010, but not in 2016? Was this file created in Office 2010?
Me: Well, actually it’s probably older than that…
DS: Oh, sir, unfortunately, the software was completely rewritten in 2013, so files created before that version aren’t compatible with later versions.
Me: OK, so what is the upgrade path? How do I make the file work for 2016?
DS: You can’t, you need to recreate the file in 2016.
Me: But I have a brand new file I created with 2016, and it has the same issue.
DS: How many versions of office do you have installed on this computer?
Me: Well, I just installed 2016, but 2010 still is on there.
DS: That is probably the issue, it isn’t supported to run more than one version of Excel on the same system.
Me: But other users who only have 2016 also have this issue.
DS: By the way I wanted to let you know, this issue you are having is being widely reported right now, and our team is working on it. I suggest you wait 48 hours and see if any updates come out to fix the issue.
Me: OK, so you are telling me that many people are calling in to Microsoft to report this Web Query Issue?
DS: Do you know the exact version of office you are running? Here, let me log into your computer to see.
[At this point, the Deflection Specialist logs into my computer by having me download the same app that the Level 2 Technician had me download.]
DS: Yes, see, you have both office 2010 and 2016 installed, let me remove that.
At this point, she removes Office 2010. Note that I actually am running Windows 10 on a VM inside my Mac, and have created a snapshot from before I installed 2016 to work on this problem, so I’m not objecting at all to her removing the only working version of Excel from my system. It is wise to have a back up plan for when you start this whole bug reporting process.
The secret to defeating the Deflection Specialist is to keep talking. Keep asking questions, keep insisting that your problem is not solved, and that she needs to pay attention to the obvious bug. At this point, your call is over an hour, and irritation is noticeable in your voice. This is a good thing, she can sense this, and will then say:
DS: I’m actually not trained on this part of Excel, so I’m going to send you to a Level 2 technician…
Me [Interrupting]: But is it a Commercial Level 2 technician? Because I’ve already spent over 1 hour on the phone, and I’ve talked to Office 365 technicians and Level 2 commercial technicians, and they keep sending me back and forth.
DS: No sir, I assure you, this is a department that specializes in Office 365 issues, and will be able to solve your problem.
After the final lie, the DS has given up, and sends you to the next level.
Level 6: “Level 2” Technician, World Circuit
This enemy is just like the original Level 2, except she gets right to the chase. You don’t get to her unless you have an actual provable bug in the product, so she doesn’t waste any time going through the motions. She still asks for the details of your bug, but then immediately asks for your authorization:
L2T: Do you have a case number?
Me: I probably should by now, I’ve been on the phone for 70 minutes, and have been passed back and forth between level 1 and level 2 support, each claiming that they can’t help me.
L2T: So sorry to hear that. Are you using Office 365 Home edition, or Business.
Me: I’m pretty sure it doesn’t matter
L2T: I need to know which version, as we service commercial…
Me: The last person I spoke with said that you would be someone that was able to understand and fix this issue. Is there anyone at Microsoft that understands Office?
L2T: Why don’t you give me your Live ID and I can look up your product version.
[A few minutes later]
Me: I’ve been sent to them THREE TIMES, and they keep sending me back to your department, I don’t think they can help me.
L2T: Sorry sir, we only service Commercial customers here, and they will be able to help you with this…
Me [Interrupting]: You can’t keep sending me over there, I want to make sure that this person knows how to deal with this bug.
L2T: I will first conference this person in, and make sure they understand the issue before letting you go, is that OK?
Me: OK, we can try that.
If you have made it this far, congratulations! Your veins may be about to burst out of your forehead, and your polite manner has probably disintegrated into terse annoyance, but the paydirt is about to come. You will now face the final challenge in the Microsoft Support Infrastructure…
Level 7: The Link Engineer
Not going to sugar-coat this, this is the final stop in your phone call. I’ll just tell it like it happened:
L2T: I have confirmed that the technician understands your issue, and will be able to help, so are you OK with me dropping off the line?
Me: Yes, thank you. [L2T hangs up]
Link Engineer: Hi, can you please describe your problem
[Repeat same description]
LE: Thank you for telling me that. Unfortunately, our office is not trained to handle these types of questions, so I’m going to give you a link to go to…
Me: Are you freaking kidding me? Does ANYONE at Microsoft know how Office even freaking works???!!! I’ve been on the phone for 80 MINUTES, and you are going to send me to a Knowledge Base article???!
LE: Sorry sir, but if you go to answers.microsoft.com…
Me: I just want to report this bug! It’s a bug, confirmed it is in Office 2016!!! Do you care about having bugs fixed in your product?!! Some answers page isn’t going to help me! I’m sick of this, you have no clue what you are talking about.
Now, hang up the phone. Don’t just hang it up. Slam it down so they know you are pissed.
Final Level: Write an Angry Blog Post
Yep, that’s it. Write one just like this one. If there’s anything Microsoft or large companies like them understand, it’s that bad PR on the Internet, especially when written in a sassy, clever fashion with references to old video games, will get people’s attention. This will persuade them to immediately start working on the bug “reported”, and it should be fixed by the next version ((disclaimer: I have no idea if this is going to work, but it really should)).
Some questions you may have, and I’ll answer them:
1. Do I have to go through the entire Microsoft Support Infrastructure gauntlet to write an angry post about my bug?
Yes you do. If you don’t have a long horrible story about phone support, it’s not as interesting, and will not gain any attention.
2. Did you know that newer versions of Excel have “Power Query” capability, and that the “Web Query” feature is pretty much obsolete?
Yes, I know that. The Web Query feature is obviously meant to be supported in 2016, as it’s in the UI. And Microsoft is famous for not breaking backwards compatibility. I also have several hundred spreadsheets that would have to be updated. Not going to do it.
3. Why do you have hundreds of spreadsheets? Why not just merge them into one maintainable spreadsheet where you could fix the problem in one place?
Because shut up.
4. What if I have paid for support from Microsoft?
Then you can report my bug for me directly. Why haven’t you? It’s really obvious and straightforward. Please?
A Final Note: I know that there are some good people working at Microsoft (with the exception of the DS), and I took some creative license in the snark describing this phone support. I really do hope they find and fix the issue, and don’t mind this ribbing.
UPDATE: Since this has been posted on HackerNews and reddit, some very nice folks at Microsoft have chimed in with some helpful tips (and all of them polite). First, I want to thank one in particular who reproduced my issue and filed a bug in their internal system. So yes, it works!
Second, here is a collection of ways that are probably better than the approach I took:
- Use the feedback button in your Office 2016 product (I hadn’t seen this before, but looks like a way to submit a pretty detailed bug report).
- Use office365.uservoice.com, for which Microsoft has many places to suggest features. The news from the insiders is that the developers patrol those regularly.
- Even though I was in a rotten mood and hung up, the last technician (the Link Engineer) was trying to send me to answers.microsoft.com. Apparently, this is also recommended as a way to get in touch with developers, but I have to say from my experience seeing some of the conversations on there, they aren’t always that good.
- If you are working with an open source Microsoft product, try to find it on github and submit an actual bug there (or even better submit a pull request to fix it).
Thank you everyone with tips, it was actually very good to see all the genuine sympathy and offers of help, especially from MS employees. Cheers!